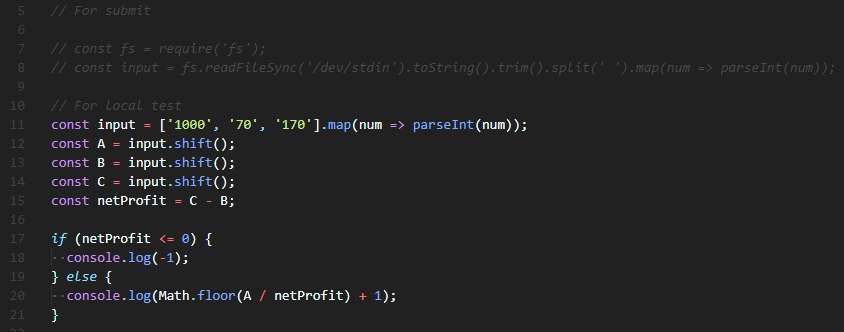
Q. 이진 트리 구조의 Node class를 작성하고, insert(삽입), contains(검색) method를 추가하라.
(생성자(constructor)는 data, left, right를 초기화 해야하며, insert()와 contains()는 data를 argument로 받는다.
또한, contains()는 해당 Node를 반환하거나 조건에 맞지 않는다면 null을 반환해야 한다.)
이진 탐색 트리의 정의(Definition of Binary Search Tree)
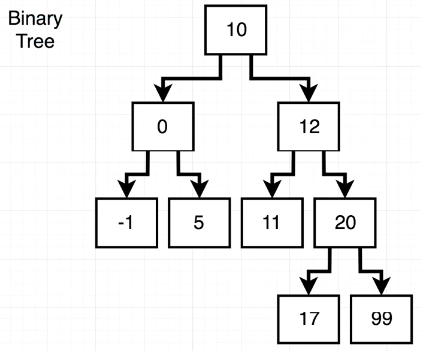
🎈 이진 트리(Binary Tree)란,
Node는 left, right 양쪽 2가지 Node만 가질 수 있으며
left는 해당 Node의 값보다 작아야하고, right는 해당 Node의 값보다 커야하는 구조를 갖는 Tree를 칭한다.
🧨constructor()는 data, left, right을 가져야할 것이고, 각 값의 초기 선언을 어떻게 해야할 지 생각해보면 된다.
insert() method를 작성하기 위해서는
검색이 필요하기 때문에 재귀(recursion)을 사용해야 한다는 것, 조건문을 잘 활용해야 한다는 것
위 2가지를 명심하고 작성해 나가면 된다.
contains() method도 insert()와 비슷한 구조로 작성되지만, 값을 return해야 한다는 것을 명심하면 된다.
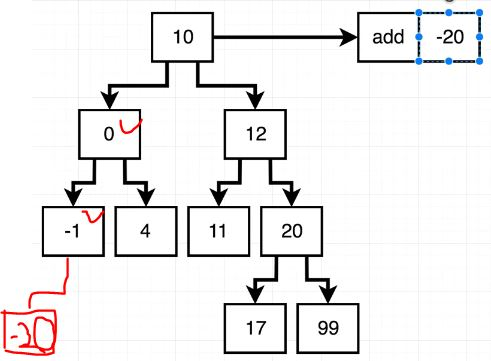
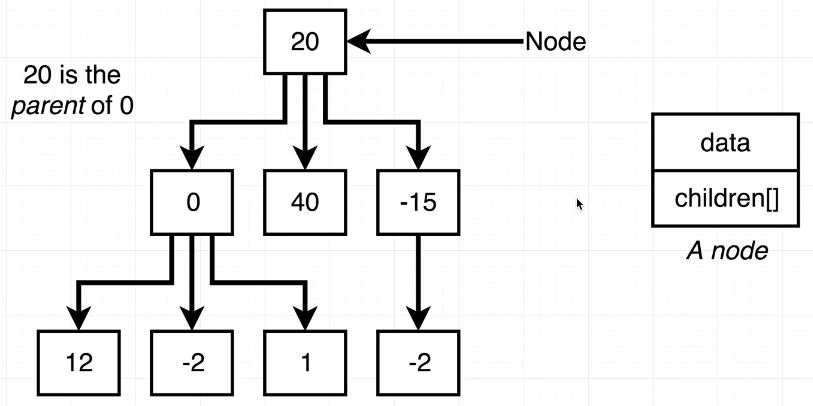
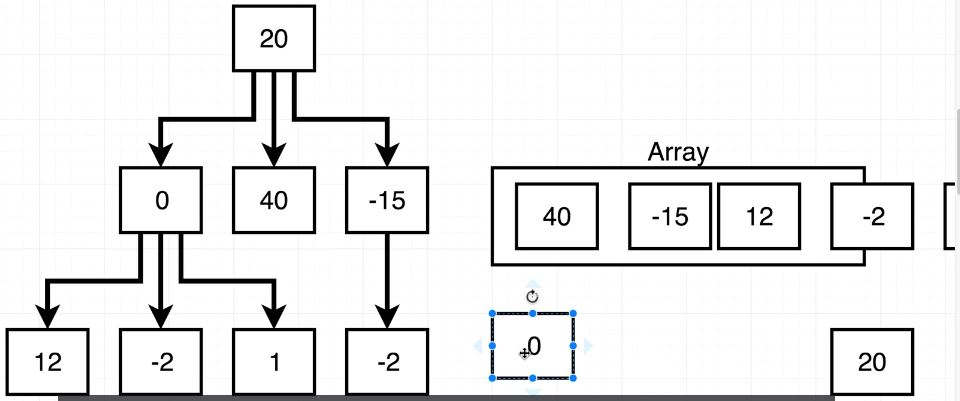
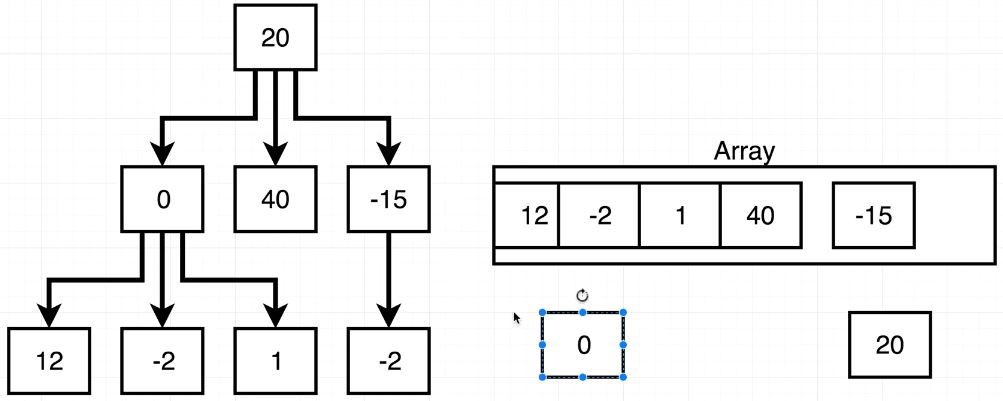
insert() method 작성에 도움이 될 만 한 이미지
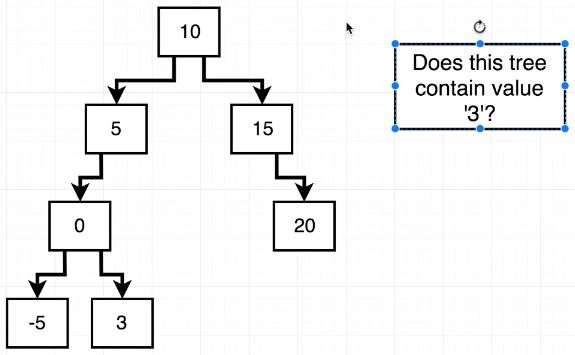
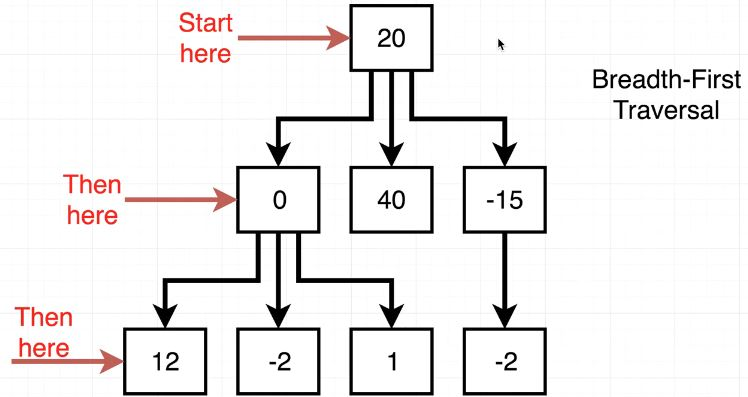
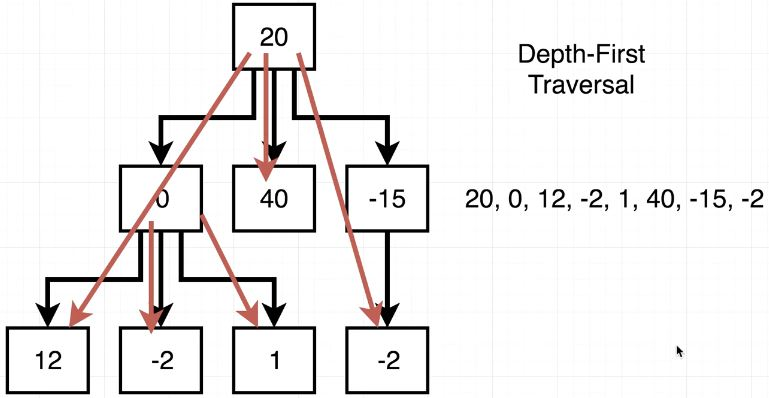
contains() method 작성에 도움이 될 만 한 이미지
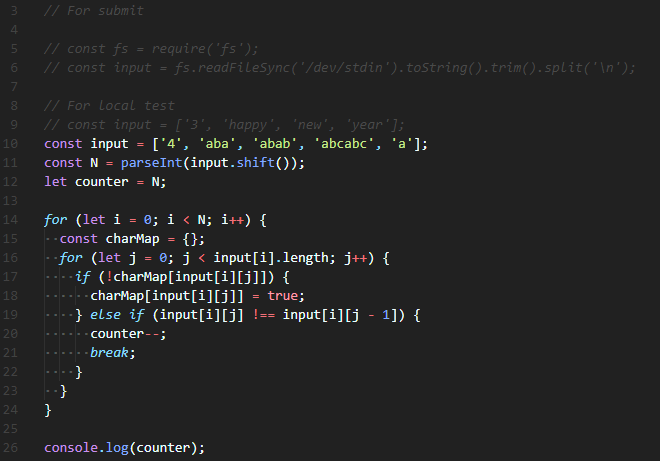
🔮 constructor()는 간단하다.
constructor(data){
this.data = data;
this.left = null;
this.right = null;}
위와 같이 작성해주면 된다.
insert() method를 작성해보자
들어오는 data가 this.data보다 작다면? 왼쪽
들어오는 data가 this.data보다 크다면? 오른쪽
왼쪽 또는 오른쪽에 Node가 있나? 있다면 재귀 insert(data)
왼쪽 또는 오른쪽에 Node가 없나? 없다면 new Node(data)
이 조건문만 잘 작성해주면 되고, 다시 검색이 필요할 때는 left or right의 insert()를 재귀로 call해주면 된다.
재귀로 다시 탐색할 때는, 한 단계 아래 tree로 이동한다는 걸 명심하자.
contains() method를 작성해보자
들어오는 data가 this.data와 같은가? 해당 Node return
들어오는 data가 this.data와 작은가? 작다면 재귀 contains(data)
들어오는 data가 this.data와 큰가? 크다면 재귀 contains(data)
들어오는 data가 this.data와 일치하는게 없다? 없다면 null return
위의 조건문을 잘 작성해주면 된다.
📌이때 명심해야할 것은, contains()에서는 조건문에 return이 필요하다는 것이다.
해당 Node를 찾거나 못 찾아도 값을 return해야하기 때문이다.
재귀를 사용하면 memory stack에 이전에 불러왔던 function이 쌓인다. 그리고 가장 나중에 진행한 function이 끝나면
마지막 function을 call한 function으로 돌아가서 작업을 마무리하게 된다.
따라서, return을 해주지 않으면, 해당 값을 끝까지 계속 지니면서 가져오지 못 한다.
insert()의 경우에는 return하는 값이 없기 때문에 return이 필요하지 않다.
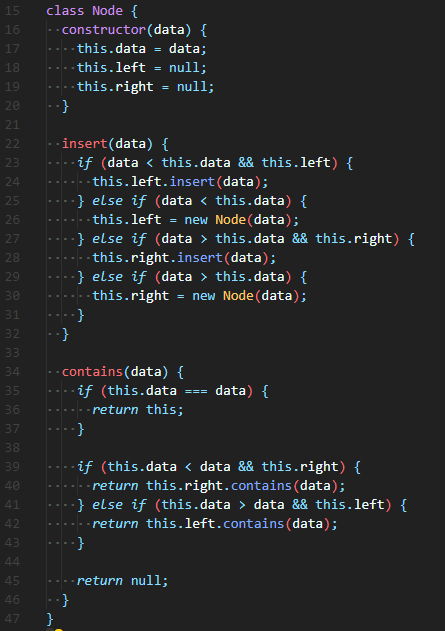
Full Code
| class Node { |
| constructor(data) { |
| this.data = data; |
| this.left = null; |
| this.right = null; |
| } |
| insert(data) { |
| if (data < this.data && this.left) { |
| this.left.insert(data); |
| } else if (data < this.data) { |
| this.left = new Node(data); |
| } else if (data > this.data && this.right) { |
| this.right.insert(data); |
| } else if (data > this.data) { |
| this.right = new Node(data); |
| } |
| } |
| contains(data) { |
| if (this.data === data) { |
| return this; |
| } |
| if (this.data < data && this.right) { |
| return this.right.contains(data); |
| } else if (this.data > data && this.left) { |
| return this.left.contains(data); |
| } |
| return null; |
| } |
| } |
'JavaScript > Data Structure' 카테고리의 다른 글
| [Tree] Validate(Binary Search Tree 이진 탐색 트리 유효성 검사) (0) | 2020.01.14 |
|---|---|
| [Tree] Level Width(트리 각 층의 너비(=개수) 알아내기) (0) | 2020.01.13 |
| [Tree] 트리(Tree) (0) | 2020.01.10 |
| [Linked List] From Last(마지막 Node에서 n번째 앞에 Node) (0) | 2020.01.09 |
| [Linked List] Check Linked List Circular(순환 Linked List 확인하기) (0) | 2020.01.09 |