✨ 선택 정렬(Selection Sort)은 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 가장 앞의 데이터와 교환해나가는 방식이다.
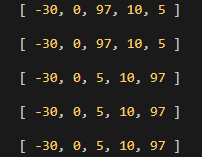
[ 10, 0, 97, -30, 5 ]
위 배열에 들어있는 숫자를 오름차순으로 정렬해보자.
Selection Sort 진행 과정
🎈선택 정렬 코드를 실행하면 위와 같은 과정으로 정렬이진행된다.
가장 작은 값의 기준은 항상 맨 앞 index이다. 하지만, 정렬이 완료되는 순서도 가장 앞부터 완료된다. 이걸 고려했을 때, 가장 작은 값의 기준은 0, 1, 2, 3, ... 씩 증가한다고 생각하면 된다.
그렇게 나머지 오른쪽 값들과 반복 비교하여 가장 작은 값의 인덱스를 저장하고, 그 값이 첫 번째 기준값과 같은 것이 아니라면 서로 값을 교환해준다.
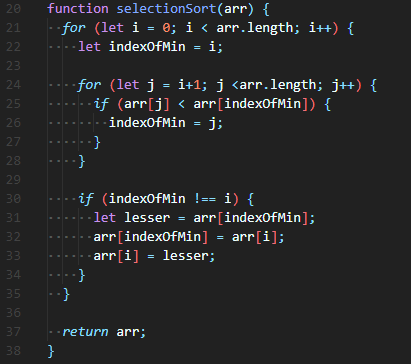
선택 정렬 수도 코드(Selection Sort Pseudo Code)선택 정렬 최종 코드
🧨 위의 코드처럼 중첩 for loop을 이용하고, indexOfMin을 외부 for loop이 진행될 때마다 새로 설정해준다. 그리고 내부 for loop에서 반복 비교해주고, 가장 작은 값의 index를 얻어낸다. 최종적으로 처음에 초기화한 i인덱스와 같지 않은 지 확인하고, 같지 않다면 서로 값을 교환해준다.
if( indexOfMin !== i ) 조건문이 들어간 이유는, indexOfMin보다 작은 값을 찾지 못 했을 때 indexOfMin은 여전히 i값을 가지고 있을 것이기 때문에 그런 상황을 대비해주는 것이다.
버블 정렬과 비교했을 때, 여전히 시간 복잡도는 O(n^2)지만 이렇게 다른 방법으로 접근할 수도 있다.
😢 이해하고 식을 만들어 내는 것이 조금 힘들었다. 미끄러지는 부분을 정확히 이해해야 한다.
😊 높이 V를 A-B로 나눠주는 방법이 가장 효율적이다. 하지만, 정상에 도착하면 미끄러지지 않기 때문에 B가 결국 한 번 더 계산식에 들어가는 셈이다. 따라서, 높이에V에 B를 빼주면 위 문제를 해결할 수 있다. 딱 떨어지지 않는 수가 나올 때는, 하루가 더 필요하다는 뜻이기 때문에 Math.ceil로 올림을 해주면 같은 효과를 볼 수 있다.
✨ 버블 정렬(bubblesort)은 서로 이웃한 데이터들을 비교하며 가장 큰 데이터를 가장 뒤로 보내며 정렬하는 방식이다.
[ 97, 5, 10, 0, -30 ]
위의 배열에 들어있는 숫자를 오름차순으로 정렬해보자.
Bubble Sort 진행 과정
🎈버블 정렬 코드를 실행하면 위와 같은 과정으로 진행 된다.
이해하기 쉽게 하기 위해서, 예시 배열 숫자에는 가장 큰 수를 맨 앞에 그리고 가장 작은 수를 맨 뒤에 넣어보았다.
첫번째 사이클에서, 이웃한 데이터를 비교해가며 index를 하나씩 증가해 나가기 때문에 가장 큰 수(97)는 맨 뒤에 자리할 수밖에 없다. 첫 번째 index부터 '앞자리 > 뒷자리'기준으로 비교하기 때문이다. 97보다 큰 수가 없다면 앞의 비교문은 언제나 참이다.
하지만, 가장 작은 수는 맨 뒤에 있기 때문에 한 칸밖에 이동하지 못 한 것을 볼 수 있다. 이 내용을 볼 때, 가장 작은 수가 맨 앞에 위치하기 위해서는 배열의 크기만큼 반복문이 반복되어야 한다는 것을 알 수 있다. 또한, 이제 마지막 index는 비교 대상이 아니라는 것을 알 수 있다. 끝 index는 이미 정렬이 끝났다. 따라서, 다음 비교 사이클에서는 index를 하나 줄여 비교를 진행해야 한다.
위의 과정이 반복되는 것이 버블 정렬이다. 이 내용을 토대로 코드를 작성해보겠다.
버블 정렬 최종 코드
🧨위에 보이는 것처럼 for loop 중첩으로 버블 정렬을 해결할 수 있다.
앞서 말한 것처럼 외부 for loop에서는 배열의 길이만큼 반복해준다. 내부 for loop에서는 외부 for loop이 한 사이클 돌 때마다, 마지막 index는 정렬이 끝나므로 배열의 길이 - i 만큼을 범위로 지정해준다. 그리고 내부 for loop에서 if 조건문을 이용해 뒤에 숫자보다 앞의 숫자가 크면 교체(swap)해주면 된다.
지금까지 버블 정렬을 이용해서 숫자를 정렬하는 방법을 작성해봤다. 하지만, 버블 정렬은 O(n^2)만큼의 시간 복잡도(Runtime complexity)를 갖기 때문에 시간적으로 굉장히 안 좋은 방법이다. 하지만, 코드를 구현하기에는 가장 쉬운 정렬 방법이다.
다음 글에서는 같은 시간 복잡도지만, 다른 정렬 방법인 선택 정렬(Selection Sort)를 작성해보겠다.
😢 어떻게 빠르게 해당 집단을 찾아낼 것인지, 해당 집안에서 정답을 어떻게 도출할 것인지가 핵심
😊 2번째 제출코드를 먼저 보면 이해하기 편하다.
다음 표는 지그재그 순서로 진행하는 분수를 더 보기 편하게 정리한 것이다.
1/1
1/2
2/1
3/1
2/2
1/3
1/4
2/3
3/2
4/1
5/1
4/2
3/3
2/4
1/5
...
...
...
...
...
...
분모는 짝수일 때, 오름차순으로(1 2 3 4 5...) 숫자가 진행되는 것을 알 수 있고, 분자는 짝수일 때, 내림차순으로(5 4 3 2 ...) 숫자가 진행되는 것을 알 수 있다. 홀수는 그 반대다.
패턴을 파악했으니, 어떻게 답을 찾아낼 지 생각해보자.
먼저, 최대로 입력받을 수 있는 수의 크기는 10,000,000이므로 배열이나 테이블로 만드는 건 시간 초과가 날 것이다. 따라서, 찾고자하는 X번을 포함하고 있는 그룹을 찾고, 그 그룹 안에서 X번째 분모/분자 값을 찾아내야 한다.
1/1부터 시작한다고 생각할 때, 해당 그룹의 분수 개수는 1부터 1씩 증가한다. 그룹 개수가 증가할 때마다 입력 받은 X에서 그룹을 빼주면 해당 그룹에 도달했을 때, X는 0 또는 음수가 된다. 위 과정을 while문에서 진행해주면 된다.
여기서 중요한 것은 groupCounter가 곧 해당 그룹의 분수 개수라는 것이다. 이 것을 기억하고 다음 단계로 넘어가보자.
이제 if (group % 2 === 0)을 이용해서 짝수일때, 분모 출력을 groupCounter + X 로 해주면 해당 그룹의 끝 기준으로 자신의 순번을 찾는다.(12345 처럼 오름차순 기준이기 때문) 그리고 분자는 1 + (-X) 를 해주면 역시 그룹의 끝 기준으로 자신의 순번을 찾는다.( 54321처럼 내림차순이기 때문)
예를 들어 11번째 분수를 찾아보자.
while(X > 0){} 코드를 통해 groupCounter는 5, X는 -4라는 것을 알아낼 수 있다. 그룹은 5번째이므로 홀수이기 때문에, 분모는 내림차순, 분자는 오름차순이다. 분모 그룹은 54321 분자 그룹은 12345 이며 분모는 1+ -(-4) = 5이므로, 5번째 그룹의 1번째 수이며, 분자는 5 + (-4) = 1이므로, 역시 5번째 그룹의 1번째 수다.
😢 보자마자 위에서 표시해 놓은 부분들이 눈에 띄었다. 각 범위를 한 바퀴 돌고 다음 범위로 넘어가는 부분인데, 각 수를 계산해보니 6, 12, 18, 24로 등차수열을 이루고 있었다. 그래서 등차수열을 이용해서 푸는 문제인가? 하고 계산식을 넣으려고 하다가 시간을 좀 낭비했다.
😊 패턴을 찾았다면 프로그래밍적으로 단순하게 작성해 나가면 된다. 최소 거리는 1부터 시작할 것이고, 범위도 1부터 시작한다. 증가하는 범위는 1,(2~)7, (8~)19, (20~)37...이므로 '기존 범위+(count된)최소 거리*6' 이다. while loop을 이용해 범위가 입력 받은 N보다 작을 때까지 반복해주면 된다.
😢 이런저런 조건들을 떠올리다보니 산으로 갔던 문제 역시 조건 그대로 코드를 작성하기 보다는, 다른 시각으로 바라보는 조건이 핵심
😊 가장 최고의 조건을 걸어두고 하나씩 물러나며 최선의 조건을 찾아야한다.
최종 제출 답안)
bigMax 변수에 가장 큰 봉지인 BIG(5)으로 설탕 무게를 나눴을 때, 나오는 숫자를 저장한다. 그리고 bigMax가 음수로 떨어지지 않을 때까지 while loop을 열어준다.
임시로 만든 tempSugar 변수에는 앞에서 계산한 bigMax 무게만큼 SUGAR를 빼준다. 만약 tempSugar가 작은 봉지인 SMALL(3)으로 나눴을 때 나머지가 없다면 최선의 조건이기 때문에 출력하고 계산을 끝내준다. 하지만, 만약 조건에 맞지 않는다면 bigMax를 1만큼 빼준다. 그런 후 tempSugar의 크기를 5만큼 높여주고 다시 3으로 나눠본다.
이런식으로 계속 반복하며 다시 5씩 늘려보고 다시 3으로 나눠봤을 때 나머지가 0이라면 계산이 가능한 설탕 무게이고, 그렇지 않고 bigMax가 음수로 떨어진다면 그건 계산할 수 없는 설탕 무게이므로 -1을 출력한다.
다른 정답자들 중에 배울 수 있었던 답안)
다른 정답자의 답안
😊 먼저, SMALL(3)의 개수를 담아두기 위한 bags 변수를 선언해준다. while loop을 무한으로 돌리면서, 설탕을 BIG(5)으로 나눴을 때 나머지가 0이라면 BIG으로 나눈 값과 bags를 합쳐 출력한다. 그리고 만약 SUGAR가 0이하로 떨어지면 -1을 출력해준다. 둘 다 해당되지 않으면 설탕을 SMALL(3)만큼 빼주고, bags를 1 증가시켜준다. (설탕을 3으로 나눈 것과 같은 의미)
즉, 이것도 역시 최고의 방법인 5를 우선으로 나눠주고, 그게 되지 않는다면 3을 하나씩 늘려가는 방법으로 해결했다. 이것도 굉장히 훌륭한 방법이라고 생각한다.
😢 21억 조건을 못 보고 반복문을 돌려 counter를 하나씩 증가시키려고 했다.. 잘못된 방법!
😊 역시나 수학 카테고리답게 다항식을 이용해서 풀면 쉽게 풀 수 있다. A는 고정 비용, B는 가변 비용, C는 판매 가격이다. 판매 누적 금액이 고정비용+가변 누적 비용을 넘어서면 손익분기점을 넘어간다. 식을 만들어 본다면,A + Bx < Cx로 만들 수 있다. 식을 정리해보자. A < Cx - Bx로 Bx를 넘겨주고, A < (C-B)x 로 정리해주면 조금 더 보기 쉽다. 즉, C-B가 0이하(즉, 0 또는 음수)로 떨어지면 손익분기점은 없다. 계속 적자다..ㅎㅎ
손익분기점이 없어서 '-1'을 출력하는 조건문은 2가지 정도로 표현할 수 있다. 1. if(C-B <= 0) { console.log(-1); } A < (C-B)x 식을 생각해서 C-B가 0이하면 손익분기점은 없다고 표현할 수 있다. 2. if(C <= B) { console.log(-1); } C-B > 0이 돼야하므로, C <= B으로 정리해주면 손익분기점이 없다고 표현할 수 있다.
😢 간단한 문제지만, 어떻게 하면 효율적으로 풀 수 있을까 고민했던 문제. 결과적으로 그다지 효과적이지 않은..
😊 결국 중첩 for loop을 이용해서 각 word의 문자를 체크하는 방법으로 풀었다. Object를 하나 만들어주고, 해당 문자가 이미 사용되었다면 charMap에 '문자': true로 넣어주었다. 만약 charMap에 이미 해당 문자가 있다면 해당 word의 index-1과 같은지 비교해주었다. 같다면 그룹단어, 그렇지 않다면 더 이상 검사할 필요가 없기 때문에 counter를 감소시켜주고, break으로 내부 for loop을 끝냈다.
😢 단순 조건문 처리로는 풀기 싫어서, 어렵게 풀려다가 생각하는 시간이 조금 걸렸다. 그리고 문제를 보자마자 Regular Expression이 떠올라서, RegExp로 풀려고 공부를 조금 했다.
😊 조건문으로만 풀기에는 뭔가 문제가 아까웠다. 그래서 이런 방법 저런 방법을 시도해봤다. (물론 단순 조건으로도 풀어봤다)
regex변수에 크로아티아 알파벳 조건들을 입력해주고 replace() 에 주입하여, 만약 일치하는 것이 있다면 공백(' ')으로 만들어줬다. RegExp 구성을 살펴보겠다. 아주 간단하다. =, -와 같은 문자들은 특수문자이기 때문에 특별하다는 뜻으로 \(backslash, escape라고도 부른다)를 앞에 붙여줘야 하고, 그 외 조건들은 |(or)문자를 사용해서 구분해주었고, g를 붙여 Global search를 해줬다.
결과적으로 2개 이상 문자를 갖는 크로아티아 알파벳은 공백으로 변경되어 1개의 문자를 갖게 된다. 따라서 결과의 length를 출력해주면 크로아티아알파벳의 개수를 알 수 있다. (조건 외의 알파벳은 1개로 치니까 따로 처리하지 않는다)
Full Code에 단순 조건문 처리로 푼 예제도 있으니 참고하길 바란다.
✔ String.prototype.replce()
크로아티아 알파벳만의 조건을 넣어서, 공백(' ')으로 변경해주기 위해 사용했다.
✔ Regular Expressions
문자열을 다루기 위한 정규표현식이다. 크로아티아 알파벳 조건을 표현하기 위해 사용하였다.
위의 Skill들은 JavaScript - helper methods 카테고리에서 간단한 사용방법을 확인할 수 있다.
😢 알파벳을 직접 손으로 입력하고 싶지 않았고, Object로 value(각 지연 시간)까지 넣어서 진행하고 싶었다. 큰 어려움은 없었고, 중심을 Object로 만들고 푸는 과정에서 어떻게 진행할지 조금 고민했다.
😊 'A'부터 'Z'까지 진행하는 for loop을 열고, 'PQRS', 'WXYZ'는 예외로 들어가도록 조건문을 걸어주었다. ( i !== 'R'charCodeAt(0) && i !== 'Y'.charCodeAt(0) )으로 조건을 넣어준 이유는, 'PQRS', 'WXYZ' 이 2가지만 제외하면 모두 길이가 3이다. 그래서 길이 3으로 저장되기 전인 R or Y에서 저장을 차단하고, 앞의 두 문자가 각각 합쳐져 길이가 4가 되었을 때 key로 저장되도록 했다.
Object를 만들어준 후에, 입력 받고 split('')한 값에 reduce달았고, 안에 Object를 반복하는 for ... in loop을 열어주었다. 그렇게 입력받은 값 중에 각 key에 해당하는 문자가 있다면, acc에 해당 key의 value를 중복 저장해주고 return 해주었다. 결과적으로 result값에 전화를 걸기 위해 필요한 시간이 저장된다.
다른 풀이도 확인해보았지만, 대부분 직접 알파벳을 입력해서 사용하였고, 특별히 다른 점을 찾지 못 했다.
✔ Object {}
{ 'ABC' : 3, 'DEF': 4 ... } 이런 식으로 전체 알파벳을 저장하기 위해 작성하였다.
✔ charCodeAt()
해당 알파벳의 ASCII Code(숫자)를 알아내서 for loop을 이용하기 위해 사용하였다.