Q. 입력 받은 Tree의 root를 이용해 Tree 각 층의 Node 너비(=개수)를 알아내는 function 작성하라.
--- Example Given: 0 / | \ 1 2 3 | | 4 5
Answer: [1, 3, 2]
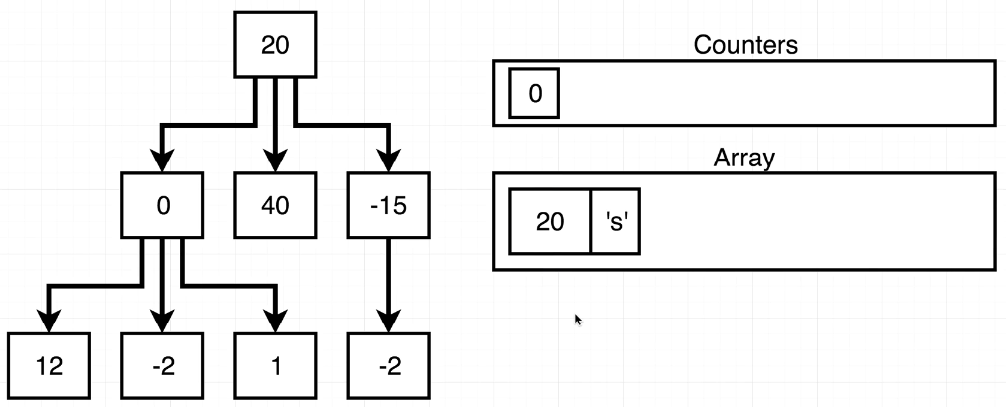
🎈 Tree traverseBF(BFS) method와 비슷하다. 배열을 선언해 초기 값으로 root와 각 층의 끝을 알려주는 문자('s')를 넣어주고, 이런 형식으로 반복 해주면 된다. 또한, 이 과정에서 각 층의 Node를 count해줘야 한다.
Tree Level Width Algorithm의 이미지화
🧨 위의 이미지를 보며 어떻게 풀어나갈 지 생각해보자
1. []의 초기값 선언 2. while 조건문은 어떻게? 3. while 내부에서 's'처리는 어떻게? 4. count 방식은 어떻게?
위 4가지만 잘 생각해주면 문제는 생각보다 쉽게 해결된다.
Tree Level Width Algorithm 정답 코드
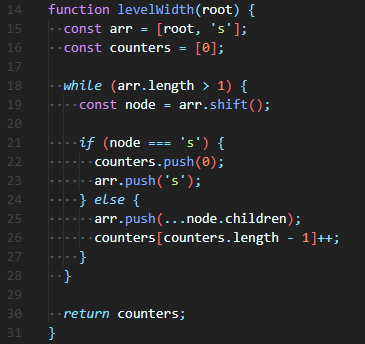
🔮 arr 배열에 [ root, 's' ]를 넣어주고 시작해야 한다. while 조건문으로 arr.length > 1을 줄 것이기 때문이다. 위와 같이 조건문을 작성하면, 마지막 's'가 남았을 때 while을 끝낼 수 있다. 여기서 counters 배열에 0을 넣고 시작하는 것도 중요한 팁이다. 보통 counter를 한다고 생각하면, count변수를 따로 만들어 count++를하고 반환할 결과 배열에 push(count)할 것이다. 하지만, 방금 작성한 방법을 사용하면 위의 while에서는 마지막 count를 결과 배열에 push하지 못한다.
전 글의 Tree traverseBF(orDF) method에서 했던 것처럼, arr.shift()을 해서 가장 첫 번째 index 값을 가져온다. 만약 's'면, 해당 width count는 끝났으며, 다음 level의 children이 모두 arr에 push된 것이므로, 새로운 counters를 push해줌과 동시에 해당 width의 끝을 알리는 's'도 push해준다. 's'가 아니라면, 위와 반대로 해당 level을 count하고 있으며, 다음 level의 children을 push하고 있는 것이므로 arr.push와 counters++를 진행해준다.
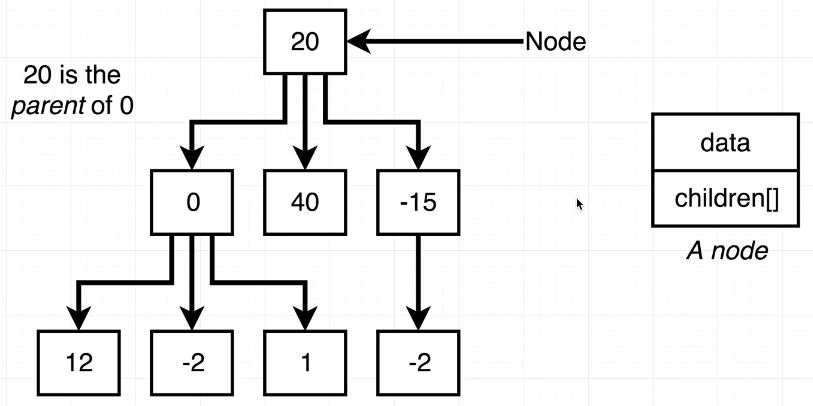
🎈 위 그림에서 볼 수 있듯, Tree는 최상위에 root를 가지며, 각 Node는 data와 children을 가지고 있다. root는 최상위 위치이기 때문에, 그 위에는 어떤 것도 존재할 수 없다. 나무의 뿌리 또는 뿌리를 제외한 나무를 뒤집어 놓았다고 상상하면 된다.
Tree는 기본적으로 추가( add() ), 삭제( remove() ) 기능을 사용하여 다루는데, 이 method는 Node class가 갖도록 작성하겠으며, Tree class 내에서는 탐색 기능인 traverseDF(), traverseBF() method를 작성해보겠다. (DFS - Depth First Search, BFS - Breadth First Search)
JavaScript의 class를 이용하여 Tree를 만들어 보자.
Node class를 먼저 작성해보겠다.
Node class
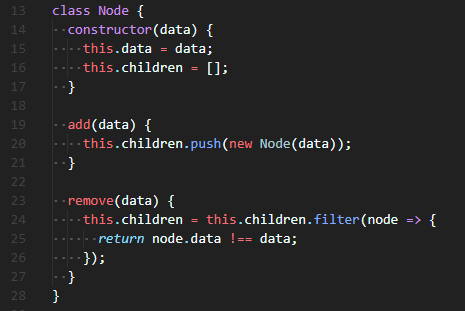
😐 지금까지 해온 것처럼, 생성자(constructor)를 이용하여 기본 변수를 선언해준다. this.data는 data를 저장하기 위한 변수, this.children은 아래 뿌리처럼 생겨날 새로운 노드를 위한 변수다.
add()는 아래 위치로 새로운 Node를 생성해준다. this.children이 배열(array)를 갖기 때문에 push를 이용해 간단히 추가해준다.
remove()는 입력 받은 값(data)과 똑같은 값(data) Node를 제거해준다. Array.prototype.filter()를 이용해서 입력 받은 값(data)과 같지 않은 값(data)만 다시 this.children으로 재할당 해준다.
Tree class
😐 앞에서 언급했던 것처럼, Tree는 Root를 반드시 가져야 한다. 따라서 생성자(constructor)를 이용해 root를 선언해준다.
먼저, traverseBF() flow 이미지를 보고 코드를 설명해 보겠다.
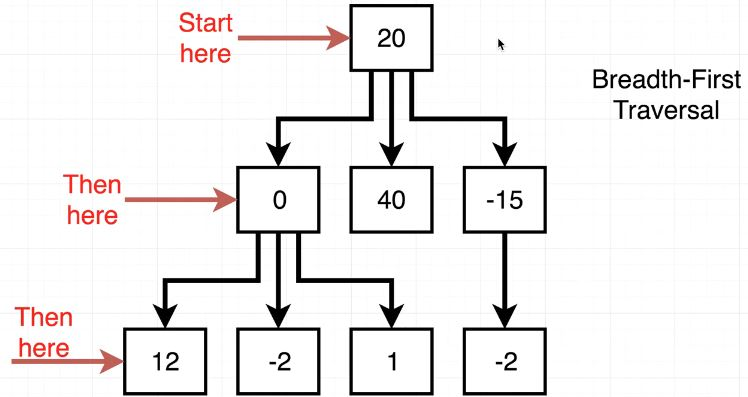
Breadth-First Traversal
traverseBF()는 너비 우선 탐색이다. root에서부터 시작하여 한 단계씩 아래 위치(층이라고 생각하면 쉽다)로 이동하여 Node를 탐색한다.
traverseBF()의 이미지화
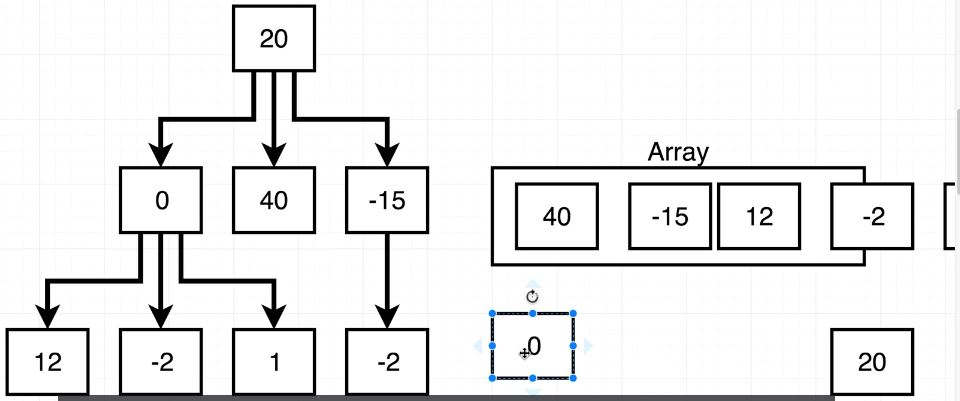
위의 이미지를 이용해 이해하면 조금 더 쉽다. 그림의 오른쪽에 Array처럼 배열을 만들어주고, 가장 먼저 this.root를 넣어준다.(Array는 탐색 순서) 그리고 while loop을 이용해 Tree를 모두 탐색하고 array가 빌(empty) 때까지 반복해주면 된다. fn은 const letters = []; traverseBF(node => letters.push(node.data);)처럼 letters에 검색한 모든 data를 넣어주는 function이다. arr에 children을 넣을 때, ES2015 Spread를 이용하면 편하지만, for ... of를 이용해도 된다.
다음은 traverseDF()다. 먼저, traverseDF flow 이미지를 보고, 코드를 설명해 보겠다.
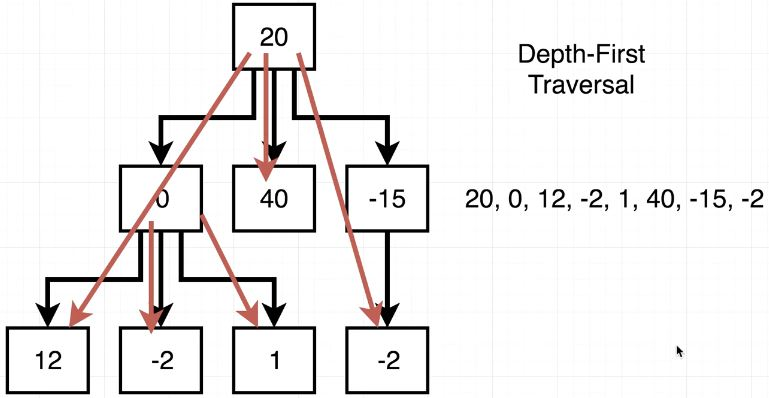
Depth First Search
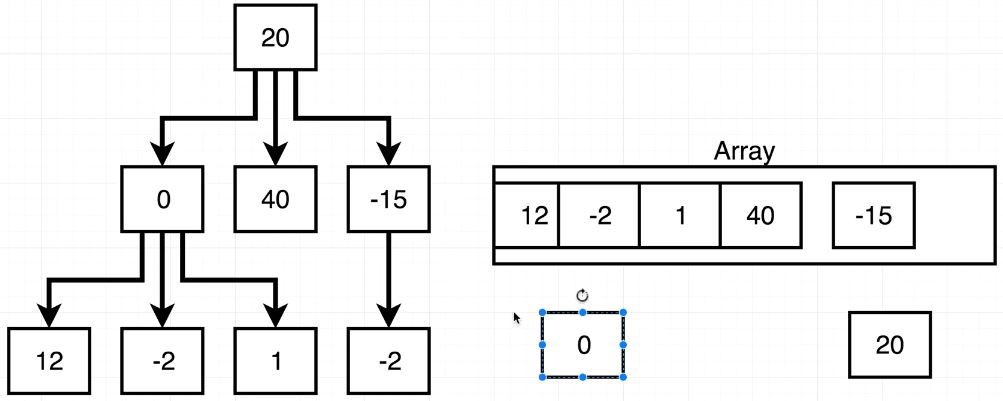
TraverseDF()는 깊이 우선 탐색이다. root에서부터 시작하여 가장 깊은 곳(가장 아래 단계)을먼저 탐색하는 알고리즘이다. 그림에서처럼 20 -> 0 -> 12 -> -2 -> 1 ... 순서대로 깊이 위치해 있는 Node부터 탐색한다.
traverseDF()의 이미지화
traverseBF()와 마찬가지로 Array를 만들어서 탐색한 Node를 순서대로 넣어준다. 20 이후에 0, 40, -15 를 갖는 Node가 Array에 들어가지만, 0의 자식 Node가 또 존재하므로, Array의 앞쪽에 Node를 넣어준다. 이 기능은 Array.prototype.unshift()를 이용해주면, Array의 가장 앞에 Node를 넣어줄 수 있다. 그리고 fn(node)를 이용해 모든 노드의 data를 letters에 저장해준다.
결과적으로, traverseBF()의 letters에는 [ 20, 0, 40, -15, 12, -2, 1, -2 ] 가 들어가 있을 것이고, traverseDF()의 letters에는 [ 20, 0, 12, -2, 1, 40, -15, 2 ] 가 들어가 있을 것이다.
위와 같이 Tree와 DFS, BFS를 작성해보았다.
다음 글에서는 Tree와 관련된 알고리즘(Level Width, Validate, Binary Search Tree)를 작성해보겠다.
Q. Linked Lists의 마지막 Node에서 n번째 앞에 Node를 반환하는 function을 작성하라.
---Examples; const list = new List(); list.insertLast('a'); list.insertLast('b'); list.insertLast('c'); list.insertLast('d'); fromLast(list, 2).data; // 'b'
🎈첫 번째에서부터 다음 n번째 Node와, 마지막에서부터 앞으로 n번째 Node의 간격은 같다. 생각의 전환! 을 생각하면 조금 더 쉽게 풀어나갈 수 있다.
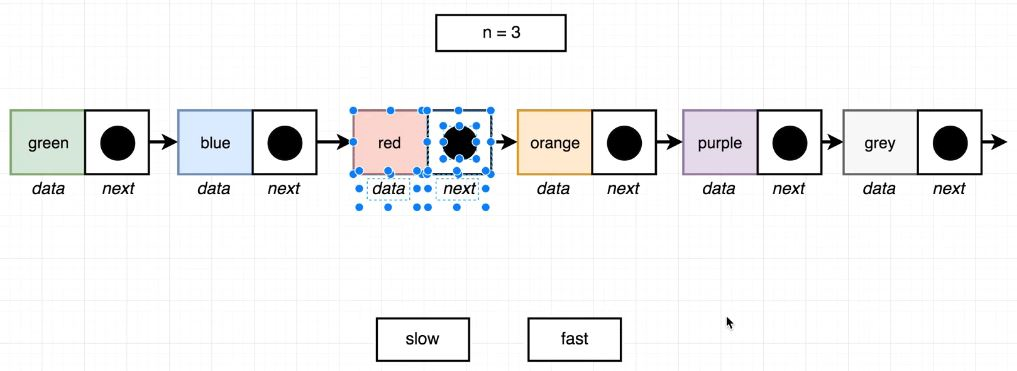
From Last 힌트 및 이미지화
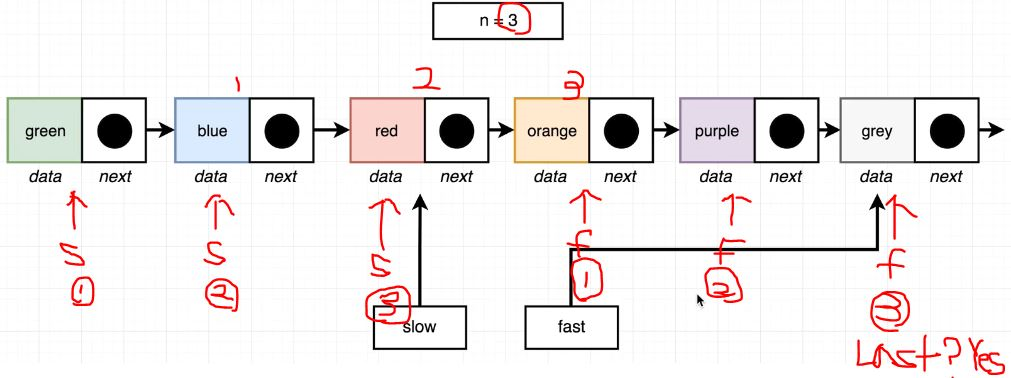
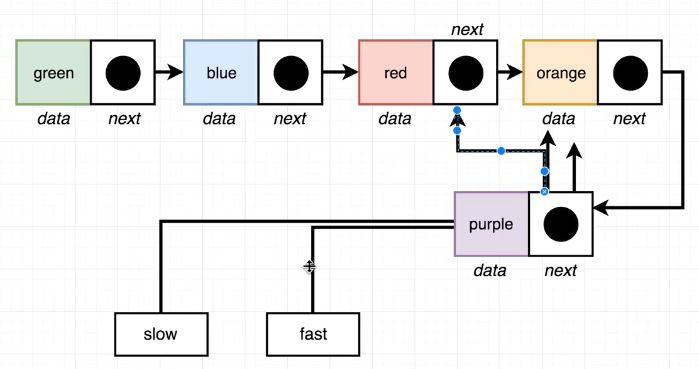
🧨 역시나 앞서 풀었던 2문제들과 비슷하다. 하지만, 생각을 조금 다르게 해야한다. 뒤에서부터 3번 앞으로 이동하면 red Node이며, 마지막 Node는 grey이고, 간격은 3이다. 앞에서부터 3번 뒤로 이동하면 orange Node이며, 첫 번째 Node는 green이고, 간격은 3이다.
만약, slow와 fast가 시작점(green)에서 시작할 때, fast를 먼저 3번 앞으로 이동해보자. 그럼 fast는 orange를 만난다. slow는 시작점인 green을 가리키고 있다. 이제 fast가 끝(grey)에 도달할 때까지, slow와 fast를 1칸씩 이동해보자. slow는 최종적으로 red를 가리키게 된다.
즉, 앞에서 이동하나 뒤에서 이동하나 그 간격은 같다. Node를 각각 반대로 생각하면 된다. 결과적으로, fast는 마지막 node를, slow는 뒤에서부터 n번째 떨어진 node를 의미하게 된다.
이렇게 뒤에서 앞에 n번째 값을 구할 수 있다.
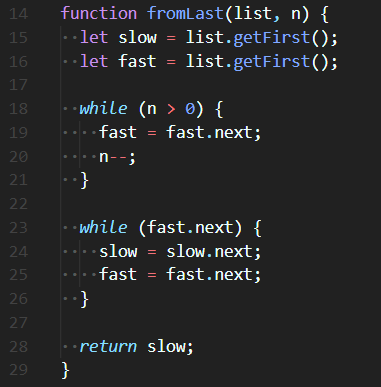
slow와 fast 진행도From Last 정답 코드
🔮 while loop을 이용해 fast를 n만큼 이동시켜주고, 또 다시 while loop을 이용해 slow와 fast를 이동시켜준다. 결과적으로 slow는 뒤에서 n번째 Node를 가리키게 된다.
Q. Linked Lists가 circular인지 확인하라(마지막 Node가 없고, 계속 순환하는 Linked List). (맞다면 true, 아니라면 false를 반환)
--- Examples const l = new List(); const a = new Node('a'); const b = new Node('b'); const c = new Node('c'); l.head = a; a.next = b; b.next = c; c.next = b; circular(l) // true
🎈 토끼와 거북이가 운동장 돌기 경주를 하는데, 경주의 끝이 없다면, 언젠가는 둘이 만날(겹칠) 것이다. 라고 상상하면 조금 더 쉽게 풀어나갈 수 있다.
Check Linked List Circular 힌트 및 이미지화
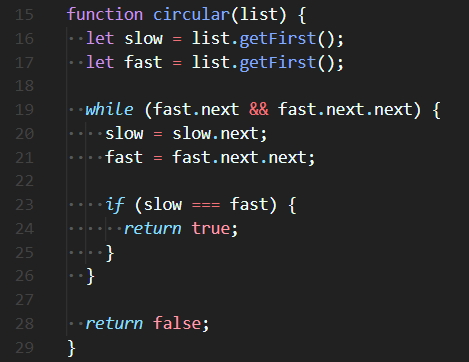
🧨 앞서 풀었던 Find the Midpoint 문제를 응용하면 된다. slow와 fast의 시작점은 같고, slow는 1칸, fast는 2칸씩 이동한다. 계속 이동하다보면 slow === fast가 되는 경우가 발생할 것이고, 이걸 조건문으로 넣어 true를 return하면 된다. 만약, circular가 아니라면 while loop조건 fast.next.next를 만족하지 않으므로 while loop이 끝난 후 false를 return하면 된다.
Check Linked List Circular 정답
🔮 while loop안에서 slow === fast 조건을 넣어주고, true가 반환된다면 이 Linked List는 Circular(순환)이며, while loop의 조건인 fast.next.next를 만족시키지 못한다면 끝이 있는 Linked List이므로 Circular가 아니다.
Q. Linked Lists의 중간 Node를 찾는 function을 구현하라. (매개변수로 list를 받으며, Lists의 크기가 짝수라면, Lists 반의 앞 부분에서 마지막 Node를 반환하고, counter변수나 size() method를 사용하지 않고 풀어야 한다)
🎈 토끼와 거북이의 경주를 생각해보자. 토끼가 거북이의 2배 속도로 달린다고 생각할 때, 토끼가 도착하면 거북이는 중간을 달리고 있을 것이다.
토끼 변수1, 거북이 변수1, 달리기 반복 loop을 이용해서 문제를 해결해보자.
Find the Midpoint 힌트 및 이미지화
🧨 slow와 fast변수는 같은 시작점에서 출발한다. 그리고 slow는 1칸씩, fast는 2칸씩 이동한다. Lists 크기가 홀수일 경우를 먼저 생각해보자. fast가 2칸씩 이동했을 경우, 항상 마지막 Node에 도착할 수 있고, 그때 slow의 위치는 중간이다. 하지만, Lists의 크기가 짝수일 경우에는 fast가 마지막 Node에 도착할 수 없다. 따라서, fast의 다음 칸은 있지만, 다음 다음 칸을 확인했을 때 Node가 없다면, 그때 slow의 위치는 중간(즉, Lists 전체 크기에서 반을 잘랐을 때 앞부분 반의 마지막 Node)이다.
위의 내용을 아래 코드로 옮겨 보았다.
정답 코드
🔮 slow나 fast를 초기화할 때, list.head;를 사용해도 동일하며, while의 조건은 반드시 &&(and)로 넣어줘야 한다.
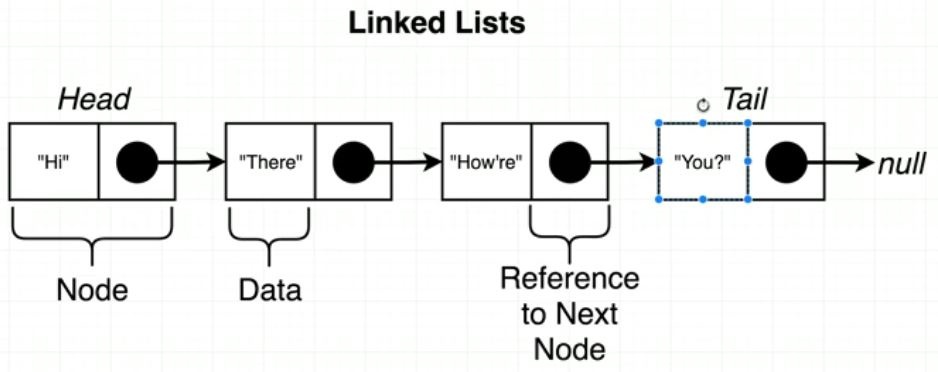
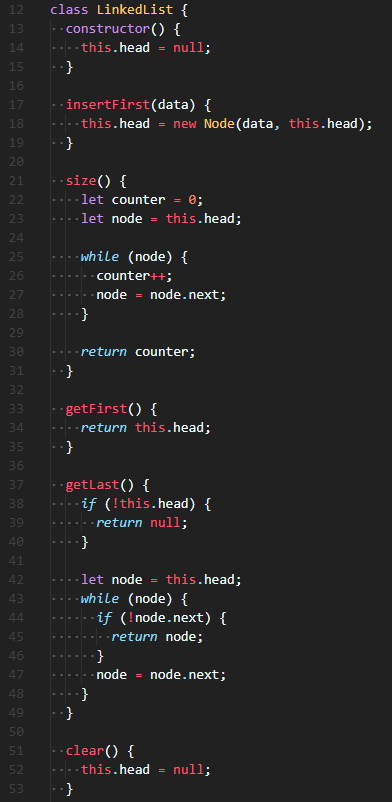
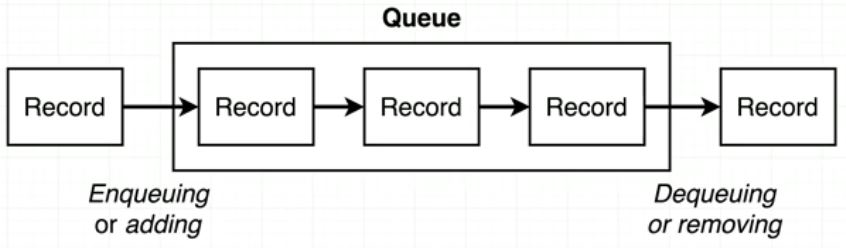
🎈 위 그림에서 볼 수 있듯, Linked List는 기본적으로 Node와 Head(or Tail까지)로 구성되어 있다. Node는 Data와 Next로 구성되어 있는데, Data는 해당 노드의 데이터 Next는 다음 Node를 가리키는 Reference를 가지고 있다. 그리고 Linked List의 맨 앞 Node는 Head가 가리키며, 맨 끝 Node는 Tail이 가리키고 있다.
Linked Lists의 method는 만들기 나름이지만, 이 글에서는 insertFirst(data), size(), getFirst(), getLast(), clear(), removeFirst(), removeLast(), insertLast(data), getAt(index), removeAt(index), insertAt(data, index) 를 다뤄볼 것이다.
JavaScript의 class를 이용하여 Node와 Linked List를 만들어보겠다.
Node class
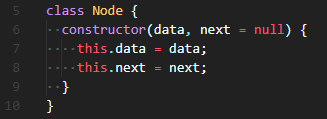
😐 Node class는 위처럼 data, next로 구성했다. next는 값이 언제 들어올지 모르므로 default 설정해준다. (default가 궁금하다면 JavaScript - ES2015를 참고해주세요)
Linked List class 1
😐 Linked List의 constructor()는 head만 선언해주었다. this.head의 시작은 항상 null.
insertFirst() method는 가장 첫 번째 list에 Node를 생성해 준다. 가장 첫 번째 List에 넣어줘야하므로, this.head에 Node를 생성해준다. 기존에 첫 번째 값이 존재할 수 있으므로, next에는 this.head를 넣어줘서, 이전에 this.head가 가리키고 있던 (과거)첫 번째 노드를 새로 만든 첫 번째 Node가 가리킬 수 있도록 reference를 재설정해준다.
size() method는 list의 크기를 알려준다. while loop을 이용해 node를 끝까지 탐색하게 해주고, node를 이동할 때마다 counter를 1개씩 증가시켜주면 된다.
getFirst() method는 list의 첫 번째 node를 반환한다. 간단하게, this.head를 반환해주면 된다. 만약 list가 비어있다면 null이 반환될 것이다.
getLast() method는 list의 마지막 node를 반환한다. if 조건문을 이용해, list가 비어있다면 null을 반환해준다. 비어있지 않다면, while loop을 이용해 node를 끝까지 탐색하여 마지막 node를 반환해준다. 여기서 중요한 것은 while loop안에 if 조건문으로, 탐색중인 node의 다음 node가 없다면, 해당 node가 마지막이므로 바로 반환할 수 있도록 작성해주는 것이다.
clear() method는 list를 초기화한다. this.head = null;을 작성해주면 간단하게 해결할 수 있다.
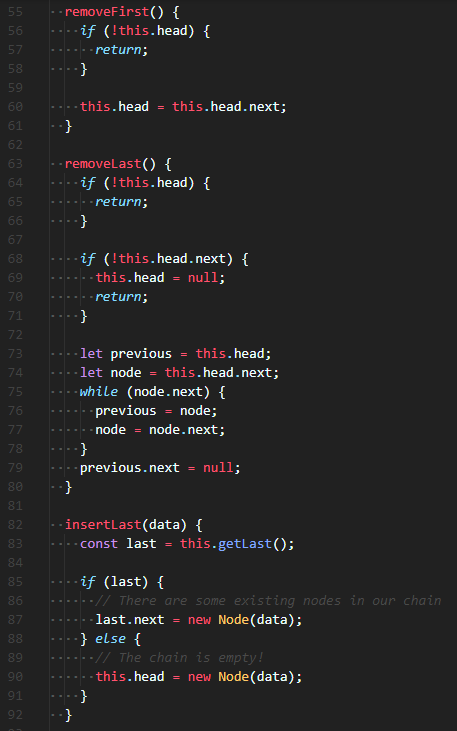
Linked List class 2
removeFirst() method는 가장 첫 번째 node를 제거해준다. this.head는 첫 번째 node를 가리키고 있고, this.head.next는 두 번째 node를 가리키고 있다. 따라서, this.head에 두 번째 노드인 this.head.next를 넣어주면, 첫 번째 노드는 제거된다. (list 그림을 상상해야한다. head가 첫 번째 노드를 가리키다가, 두 번째 노드를 가리킨다고 생각하면 된다)
removeLast() method는 가장 마지막 node를 제거해준다. list가 비어있을 경우, list에 node가 하나일 경우를 먼저 조건문으로 처리해줘야 한다. (previous와 node를 사용할 것이므로 적어도 node가 2개 이상 돼야 한다.) 탐색을 하기 전에, 제거할 node의 이전 node를 가리키는 previous, 제거할 node인 node를 선언해준다. while loop안에서 지금까지 해왔던 탐색과 마찬가지로 node를 이용해 마지막 node를 찾은 후, previous.next에 null을 넣어줘서 마지막 node를 제거해준다.
insertLast(data) method는 list의 가장 마지막에 node를 생성해 준다. 직접 작성해줄 수도 있겠지만, 여기서 이전에 작성한 method를 재사용해줄 수 있다. 바로 getLast() method다. 마지막 node를 찾아줄 getLast()를 사용하고, 만약 last가 있다면 last의 다음에 node를 생성해주고, 만약 last가 없다면 list가 비었다는 것이므로, this.head에 node를 생성해주면 된다.
Linked List class 3
getAt(index) method는 원하는 index의 node를 찾아준다. size() method를 작성할 때와 비슷하게, counter를 선언해주고 while loop을 이용해 탐색한다. while loop 안에서 if 조건문을 이용해 만약 index와 counter가 같다면 해당 node를 반환해준다. while loop 안에서 못 찾았다면, index값이 list의 개수를 벗어나거나, list가 비어있는 것이므로 null을 return해준다.
removeAt(index) method는 해당 index의 node를 제거해준다. 해당 node를 제거하려면 이전 node도 알아야하기 때문에 적어도 node가 2개 이상이어야 한다. 따라서 list가 비어있을 경우와 list에 node가 1개만 있을 경우를 조건문으로 처리해준다. 그리고 여기서도 기존 method를 재사용할 수 있다. 바로 this.getAt(index)이다. this.getAt(index-1)을 이용해 previous를 찾아내고, previous가 탐색 범위가 넘어갔을 경우를 조건문으로 처리해준다. !previous는 아예 범위가 벗어난 경우, !previous.next는 previous는 찾아냈지만, previous가 마지막 node인 경우다. 만약 위의 조건문에 걸리지 않는다면, 정상적으로 해당 node 제거가 가능하다는 것이므로, previous.next에 previous.next.next를 넣어준다. 이렇게 처리해주면, previous와 previous.next.next 사이에 있던 node를 제거할 수 있다.
insertAt(data, index) method는 해당 index에 node를 생성해준다. 여기서도 해당 index의 이전 node를 가리키는 previous를 사용해줘야 하기 때문에, list가 비어있을 경우, list에 node가 1개만 있을 경우를 조건문으로 처리해준다. 이전과 다르게, 위의 조건문에 걸렸을 경우에는 바로 node를 생성해주고 return한다. 여기서는 2개의 기존 method를 재사용해줄 수 있다. 바로 getAt()과 getLast()이다. getLast()를 사용하면 insertAt에 list의 범위를 넘어간 index를 넣었을 때, list의 가장 마지막에 node를 생성해줄 수 있다. previous.next를 가리키는 node를 생성해주고, previous.next에 새로운 node를 넣어주면 된다. (머릿속으로 Linked List이미지를 상상하자)
🎉 위의 방법으로 JavaScript를 이용해 Linked List를 작성해줄 수 있다. 다음 글에서는 Linked List를 이용한 Algorithm들을 살펴보겠다.
Q. 2개의 스택(Stack)으로 큐(Queue)를 만들어라. (어떠한 array도 만들어서는 안 되며, Stack의 push(), pop(), peek() method만 이용하여 작성해야한다)
정답 예시(Queue from Stacks)
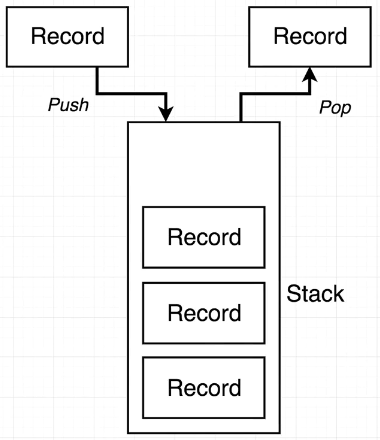
🎈 먼저, Stack의 특징인 LIFO(Last In First Out)와 Queue의 특징인 FIFO(First In First Out)를 생각해야 한다.
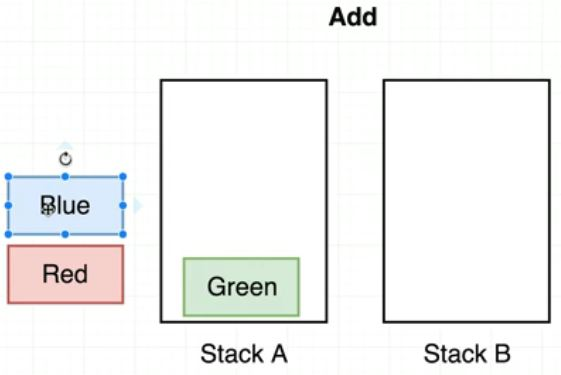
Add()
큐의 add()를 구성하고 싶다면, 위의 그림처럼 그냥 1번 스택에 값을 넣어주면 된다. 이건 생각하는 것에 문제가 없다. (편의상 앞으로 a스택, b스택이라고 이름을 정하고 얘기하겠다) 하지만, remove()와 peek()을 구성할 때 순서에 문제가 생긴다.
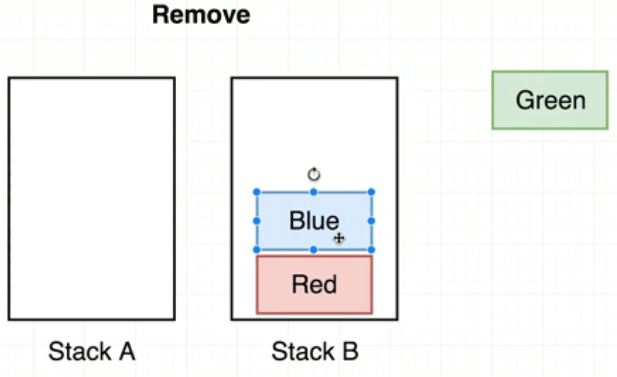
peek()
remove()를 구성하기 전에, peek()을 먼저 생각해보자. a스택에서 마지막에 들어간 값을(this.data[this.data.length -1]) return 해버리면 LIFO 순서로 값이 나와버린다. 따라서, 큐의 peek()를 구성할 때 LIFO를 FIFO로 바꿔줘야 한다. 그러기 위해서 a스택의 값을 pop()하여 b스택에 push()한다고 상상해보자. 위의 그림처럼 값이 옮겨질 것이다. 이렇게 값을 옮긴 후 b스택의 마지막 값을 가져오면 Queue의 peek()과 동일한 결과를 얻어낼 수 있다.
peek()과 구성은 같으며, 값이 제거되느냐, 아니냐의 문제다. 이렇게 값을 옮긴 후 b스택의 마지막 값을 pop()해주면 Queue의 remove()와 동일한 결과를 얻어낼 수 있다.
단, peek()과 remove()에서 모두 b스택으로 옮긴 값은 원하는 처리 후 다시 a스택으로 옮겨줘야한다.
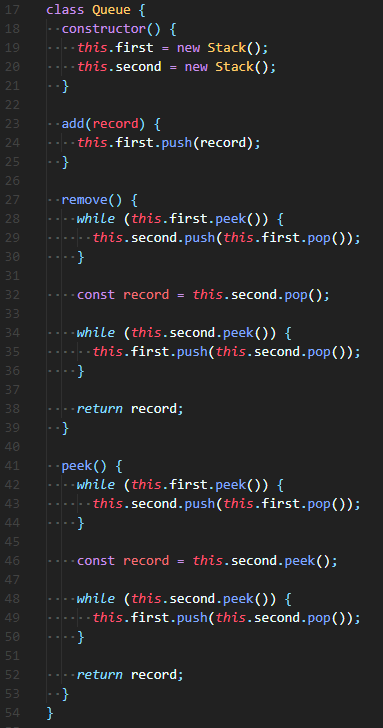
정답
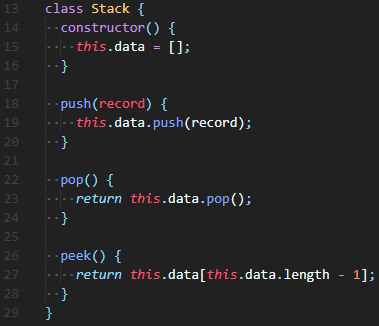
🔮 생성자(constructor)에 2개의 스택(Stack)을 생성해준다. (단, Stack class를 가져오거나 따로 작성해둬야 한다)
add()에서는 a스택에 값을 push()한다.
remove()에서는 a스택 값을 b스택으로 옮긴 후 제거한 후, 다시 b스택 값을 a스택으로 옮겨준다.
peek()에서는 remove()와 마찬가지로 스택간 값을 옮겨주고 마지막 값을 가져온 후, 다시 값을 옮겨주면 된다.
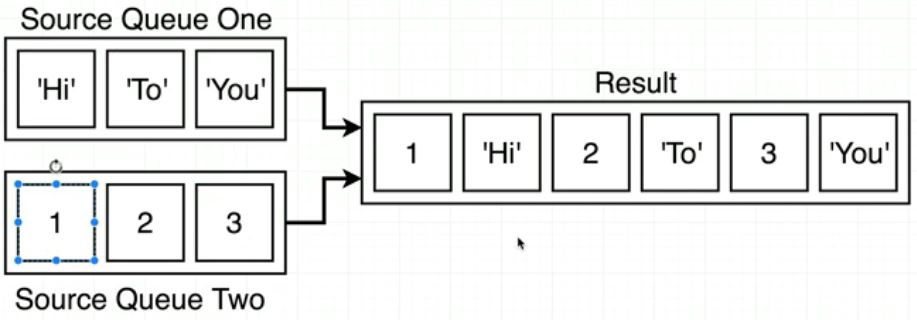
Q. 값을 다르게 가지고 있는 2개의 큐(Queue)를 1개의 큐(Queue)로 만드는 weave 함수(function)을 만들어라. (단, 값을 번갈아 넣어야하며, undefined는 없어야 한다. 또한, 어떠한 array도 만들어서는 안 되며, Queue의 add, remove, peek method만 이용하여 작성해야한다)
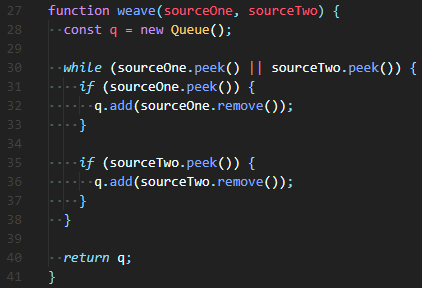
정답 예시
🎈 먼저, 값이 많이 있기 때문에 반복 작업이 필요하다. 그러니 '반복문'을 먼저 떠올려야할 것이다. 그리고 undefined가 들어가면 안 되니, 값이 있는지를 확인하는 '조건문'이 있어야한다.
값이 있는지 확인하는 peek()을 반복문의 조건으로 넣을 수 있을 것이다. 값이 있다면 '반복'해야하니까. 그리고 또한 한쪽의 값이 먼저 다 소진될 수 있으니, 반복문 안에서도 값이 있는지 또 확인하는 조건문도 필요하다.
조건이 맞는다면 해당 큐에서 값을 제거한다. remove() 그리고 새로운 큐에 값을 넣어준다. add()
위처럼 간단하게 생각하고 시작하면 된다.
🔮 가장 먼저, 새로운 큐를 만들어줘야한다. const q = new Queue(); 반복문의 조건은 while( srcOne.peek() || srcTwo.peek() )을 넣어 둘 중 하나의 큐에 값이 있다면 반복한다. 조건문은 if ( srcOne.peek() ) 와 if ( srcTwo.peek() )을 넣어줘서, 둘 중 하나의 큐라도 값이 있다면 실행시킨다. if의 내부에서는 q.add( srcOne.remove() )를 통해 기존 값을 새로운 큐(q)에 넣어준다.